Unfortunately it is not possible to update/patch your SharePoint infrastructure without occurring some amount downtime. So the only options available to us are to minimize downtime. Not only updates or patches causes downtimes; but solution deployments as Web Application deletions can provoke downtimes. This is very a bad User Experience for users if you don’t have a governance or well defined Service Level Agreement (SLA) about your SharePoint Infrastructure.
According to Microsoft there are a few methods available to minimize the amount of downtime; however it’s just not possible to achieve a zero downtime solution for your upgrade. A common way to minimize downtime is via implementation of a parallel upgrade farm. There is a real difference between “not available” and “reduced functionality”. As great example of a reduced functionality is something like a read only farm that gives you the availability to check your site; but not edit or delete a document. Once patching on the primary farm is complete the user requests can be redirected to the primary farm.
The main goal of this article is to show you how you could try to achieve the cloud SLA of Microsoft; if even that is quite very difficult.
Infrastructure Upgrade vs Solution Update
Take the example that you want to install any Cumulative Update (CU), Service Pack (SP) or even update a globally deployed solution. We know that we must manually run PSCONFIG after installing any SharePoint patches. The SharePoint binary files are updated with the patch but the databases are not automatically upgraded. SharePoint runs in a compatibility mode that still allows the sites to function with the older version databases. That’s the reason why; http://blogs.technet.com/b/sbs/archive/2011/05/24/you-must-manually-run-psconfig-after-installing-sharepoint-2010-patches.aspx
In order to update the SharePoint databases, you must manually run the PSconfig utility. To run the utility:
- Open an Administrative command prompt.
- Change directory to C:Program FilesCommon FilesMicrosoft SharedWeb Server Extensions14BIN
- Run exe -cmd upgrade -inplace b2b -force -cmd applicationcontent -install -cmd installfeatures
Your SharePoint Farm will be inaccessible while the command is running. The amount of time the command takes to run will vary on the size of the database and the speed of the machine.
The same scenario can be applied on globally deployed solutions. Avoid creating a lot of global SharePoint Packages and try instead to provision as much as you can to specific Web Applications. Every time you touch a global SharePoint Package all Applications Pools will be stopped/recycled. Although there are some scenarios when you can’t avoid creating global SharePoint Packages, you should try to avoid them.
A major rollout without downtime; this is the requirement of our business. Unfortunately it’s not possible to update your SharePoint Platform without having some amount downtime. But we can optimize our SLA (99, 85%) in your On-Premises SharePoint Infrastructure with PoSH
Possible Solutions
The use of a common data store for all SharePoint farm members and the dependency on IIS, means that you cannot update a SharePoint farm without “some” downtime unless a fully synchronized standby farm is available (so, deploying SharePoint Packages means outage to your Web Applications).
Stretched Farms
A great example is the Stretched Farm, even if it is not a perfect solution.
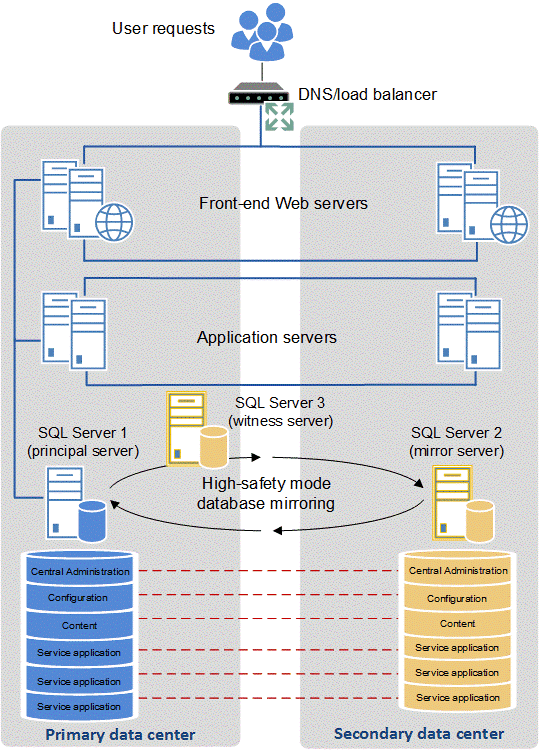
For stretched farm architecture to work as a supported high availability solution the follow prerequisites must be met:
- There is a highly consistent intra-farm latency of <1ms (one way), 99.9% of the time over a period of ten minutes. (Intra-farm latency is commonly defined as the latency between the front-end web servers and the database servers.)
- The bandwidth speed must be at least 1 gigabit per second.
The TechNet Article has more information about the Stretched Farms: here.
Disadvantages:
- Budget – you’ll have to double your infrastructure
- Operations – more servers to manage
- Licensing ( SQL Server for Always On, SharePoint Server Licenses, …)
- Datacenter costs
- …
SharePoint Read-Only Farms
The functionality and user experience in a read-only farm depends on which databases are set to read-only. A farm that uses read-only content and service application databases is likely to be part of a disaster recovery environment or a highly available maintenance, update, or upgrade environment.
You may choose a switching mechanism (DNS, load balancing, etc.), that meets your needs. Read more about this configuration, its caveats, & the end user experience it provides: Run a farm that uses read-only databases (SharePoint Server 2010) http://technet.microsoft.com/en-us/library/dd793608(v=office.14).aspx
Local Deployment (only for Solution Update)
In a local deployment, solution files are deployed only to the computer from which the deployment operation was initiated. The solution is not marked as “deployed” in the configuration database until the solution files are deployed to all applicable servers in the server farm. Then solution features are installed, and schema and definition files are committed to the configuration store. https://technet.microsoft.com/en-us/library/cc262995(v=office.14).aspx
There are some situations where this way of deployment just does not work, especially when the solution updates the content and code at the same time. The content is in the Databases and shared by all the Web Front Ends. So, you should first consider what type of customizations you do and which allow for zero downtime and which not. Note Web services can be deployed and only recycle the used app pool.
Another example, assuming you’re only updating a .dll:
- Disable the timer job on all front-ends
- On the Central Admin server (not load balanced), Update-SPSolution
- For each of the front-ends
- Take the front-end out of rotation
- Launch stsadm –o execadmsvcjobs. This will cause the upgrade to execute on that particular front-end only.
- Bring the front-end back into rotation
- Enable the timer job
Administrator’s Solution Update Checklist
Although this approach will for most cases work there are a few gotchas that you need to watch out for. In some of these occasions all SharePoint WFEs will have their application pools restarted or database schema’s are updated.
1) Try to Avoid –Force when Executing a Script!
Use the Force switch only for fixing broken deployments of SharePoint Packages. Not only it makes SharePoint stop affected Application Pools but also it prevents you from seeing errors should there be any.
2) Retracting Packages
There is a recycle on the Application Pool, Why don’t you do this at 04:00AM (with task scheduler). On Each front-end Web server, the following occurs:
- Microsoft Internet Information Services (IIS) is disabled.
- Files are removed from the system.
- IIS is re-enabled and Windows SharePoint Services is reloaded when a user browses to a page.
3) Scope your Solution
When a solution is deployed globally, all SharePoint application pools, including Central Administration’s, are recycled automatically. This can be good and bad. This is good because any GAC installed DLL that has been upgraded needs to be reloaded. This can be bad though with regards to the availability of your entire SharePoint Farm.
4) Reduce the Amount
Do not create a WSP for layout Pages, CSS. Try to minimize the amount of solutions. ‘Aspx’ files, DLL and controls are going to the application domain and these files have to be compiled. Layouts, CSS, resources not!
5) Separated Application Pools
Many websites can be hosted on one Application Pool, but Many Application Pools cannot be used by a Web Application. So the question can be how can I manage my Web Applications while keeping in mind the 12 Web Application Pools Limit? Well, all the Application Pools should be together by usage or anything else and divided by authentication model (claims, anonymous …) or HNSC should be solution for you.
Administrator’s Infrastructure Upgrade Checklist
1) Remove from Load Balancer
If you have a (fully) redundant SharePoint Farm (meaning several Web Front Ends and/or Application Servers) you can remove the server that you want to patch from your Load Balancer and send all requests to others. By this way you can apply any patch on your servers and run the PSConfig after business hours. You can/have to apply this methodology to all servers, because otherwise the Product Configuration Wizard shall claim that the servers aren’t on the same
2) Regroup Operational Tasks
It’s not always possible, but try to regroup all operational tasks like deleting the Web Application, installing a new solution or an Index Reset on your Content Sources. Every operation to the Web.config will recycle the Application Pool (if not globally deployed. Your documents won’t be available until the index rebuild etc…. You can even automate the deletion, creation or modification of a Web Application with PoSH and schedule it with Task Scheduler. This will prevent frustration and unhappy users.
3) Script as Much as Possible
To prevent any human errors or forgetting’s; it’s always preferable to script with PoSH. Human being can make errors, scripts not!
4) Use the SharePoint Object Model
The main advantage of using the Object Model (OM) is that if you need to change anything (enabling caching …) manually in the Web.config (with I strongly do not recommend), well these changes are automatically done on all other WFEs!
5) SP, CU, PU, SU …
Install updates and patches when you encounter an issue that is addressed by the update. The only exception is you should try to maintain some reasonable level of update. It is not ideal to let your environment lapse two years behind in SharePoint updates. Stefan Goßner. Ever heard about that name? Well if not, that means that you’ve never patched your Servers correctly. I strongly recommend you to read his articles. A great one about patching here. To prevent and avoid any downtime and unhappy users you should patch your servers outside the business hours and/or in the week-end. Every update should be applied to a test environment and thoroughly tested before applying said update to production. Also VM snapshots are not supported by Microsoft. Official statement: Do not use the Hyper-V snapshot feature on virtual servers that are connected to a SharePoint Products and Technologies server farm. This is because the timer services and the search applications might become unsynchronized during the snapshot process and once the snapshot is finished, errors or inconsistencies can arise. Detach any server from the farm before taking a snapshot of that server.
6) Log-Shipping
It’s of course possible to run a SharePoint web-farm that doesn’t go offline during a patch process if you have a Disaster Recovery (DR) farm to lean on while you patch the main SharePoint farm. This is article is about how that’s done but in short it involves using said Disaster Recovery farm with SQL Server log-shipping enabled as per this article, in read-only mode. This is true high-available SharePoint patching explained. Please refer to this article: http://blogs.msdn.com/b/sambetts/archive/2013/11/15/patching-sharepoint-farms-with-no-downtime-high-availability-sharepoint.aspx
7) Alias
By using a SQL Server alias or a DNS alias, you’ll be able to change the database server in your SharePoint farm or even change a SharePoint Server in your farm, without anyone in your organization even knows you’ve made a change. This technique is useful when moving your database server, setting up a test environment, or especially for migrations.
8) Separate Datacenters
SharePoint 2013 has been optimized to work well over wide-area network (WAN) connections. You can deploy your SharePoint Farm over several countries on different Datacenters or deploy in one country in one or more regions. The main advantage is that, if something goes wrong with a datacenter the other one(s) still can continue to work without any interruption. For more information about Global architectures for SharePoint Server 2013 please refer to this TechNet article: https://technet.microsoft.com/en-us/library/gg441255(v=office.15).aspx
9) Dynamic Memory
Microsoft doesn’t support the “Dynamic Memory” option for VMs that run in a SharePoint 2013 environment. The reason is that this implementation of dynamic memory does not work with Distributed Cache and Search. This can cause performance degradation and even downtime if you’re OS or other components needs to use the memory for other stuff (site not answering, Application pools recycle when memory limits are exceeded, and bla bla bla)
10) SQL Server AlwaysOn – SharePoint 2013 High Availability and Disaster Recovery
I don’t think I need to write many lines about Always-On; a great feature on SQL Server. What makes it so attractive is that AlwaysOn provides automated high availability at a database level ( héé oohh SharePoint uses DBs, remember 🙂 ) without the need of creating SQL cluster. However, it does require Windows Failover Clustering Service (WFCS). http://blogs.technet.com/b/salbawany/archive/2014/07/06/sql-server-alwayson-sharepoint-2013-high-availability-and-disaster-recovery.aspx
Why is my SharePoint Farm down each time I’m Deploying, Retracting or Upgrading a Solution?
Deploying a Solution
Initially, the package manifest is parsed to find assemblies, application pages, JavaScript, CSS Files and other files that are not part of a Feature. These are copied to the locations specified in the manifest. All files contained within a Feature are copied to the Feature directory, a subdirectory of %ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14TEMPLATEFEATURES. After solution files are copied to the target computers, a configuration reset is scheduled for all front-end web servers; the reset then deploys the files and restarts Internet Information Services (IIS). Farm administrators can specify when this occurs. http://msdn.microsoft.com/en-us/library/aa544500.aspx
Retracting a Solution
Retracting a solution is the process of removing assemblies, files, resources, safe control entries, Features, and other solution components from computers to which they have been deployed. In a complete retraction, features are uninstalled first from front-end web servers in the farm. If the solution is web application–specific, solution global files (if any) are removed when the solution is retracted from the last web application to which it is deployed.

Upgrading a Solution
There are two ways to upgrade a farm solution. Which one is used depends on what kinds of changes have been made in the newer version of the solution.
Replacement: The old version of the solution is retracted, and optionally removed from the farm solution store. The new version is then added to the solution store and deployed. It is not necessary that the new solution package (.wsp file) have the same name or GUID as the old version, however, if the old version is retracted but not removed from the solution store, then the new version must have a different filename and GUID. This kind of upgrade must be used if the new version of the solution differs from the installed version in any of the following ways.
Update: A new version of the solution package is installed and deployed which has a different file name but the same GUID as the old version. The Microsoft SharePoint Foundation deployment infrastructure detects that the GUIDs are the same. It automatically retracts the old version before deploying the new version. If there are Features in the solution, then the new and old versions have the same set of Features and they remain activated but assemblies and certain other files in them are updated with the versions from the new solution package. http://msdn.microsoft.com/en-us/library/aa543659.aspx
Business Case: 46 Application Pools
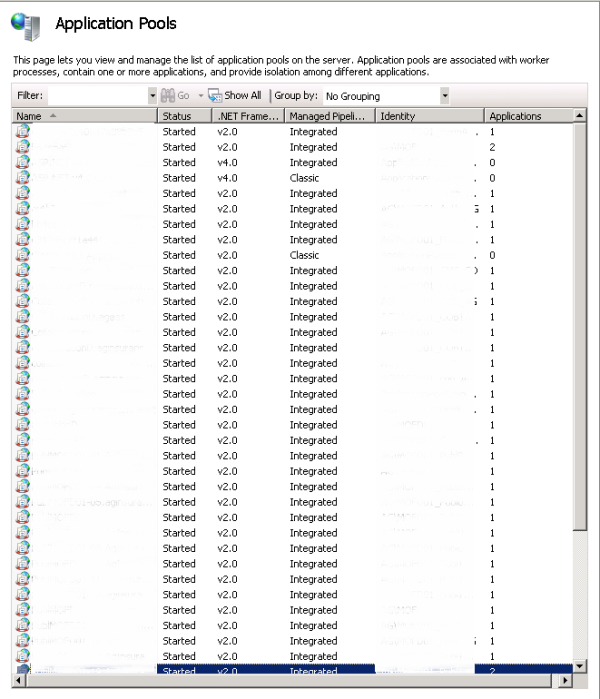
The Microsoft recommended amount of IIS application pools per server is 10. These recommendations are dependent on hardware and load most of the time, but not during IIS Reset. During an IIS Reset all the application pools are brought down alphabetically and then brought back up. This takes +- 10 seconds per application pool. How more application pools, how more downtime.
I’ve tested deployment times on Development / Test machines and here are the results for deploying the same solution on different servers with different amount of application pools running.

As you can see there is a consistent rise in deployment / downtime and the number of application pools.
Business Case: Workaround
A simple calculation shows us the following: 9:00min X 10 solutions => 90 minutes downtime of your SharePoint Farm (DEV). The business is not happy with that cause their site is down and they cannot use it anymore for 90 minutes at least.
The question can be; why is SharePoint stopping one by one the application pools? What if I stop all the Application Pools manually, made my modification and start my Application Pools again manually?
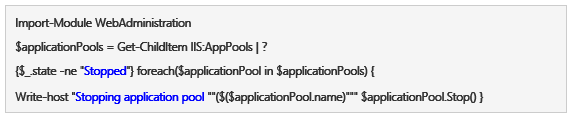
Stopping Application Pools Manually
On my server with 46 Application Pools it isn’t easy to bring each of them down. You can use the following script to bring down all your Application Pools:
Updating the Solution
When all the Application Pools are down please update your solution with the Update-SPSolution command (an example can be):

We can now check the SharePoint Logs:
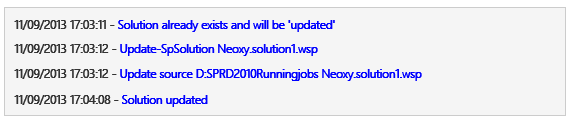
Now that was fast! 1 minute in place of 9 minutes… Why? Cause we stopped manually the application pools and didn’t wait for the stop and start of each Application Pools that took a crazy time. Now we have to restart the 46 Application Pools again. You can use the following script to start all the application pools under your current farm.
Starting Application Pools Manually
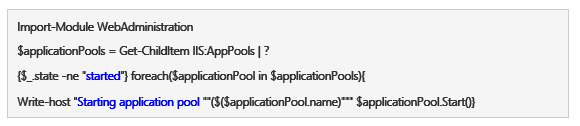
The Deployment Process is a Black Box
After several days of discussion with @Microsoft and several tests on our Dev machines, here are the results of our tests on the behavior of pools Application.
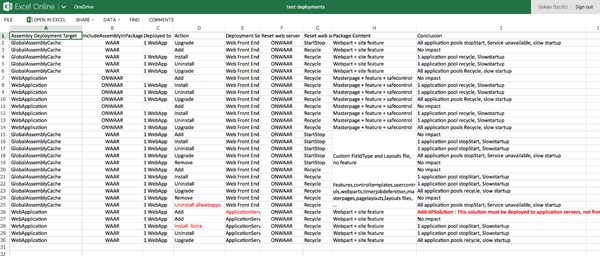
Please hit ME or the image to download the Excel Sheet!
According to @Microsoft: (Note these remarks are valid for globally deployed solutions as deployments targeted towards particular applications should not have any impact on other web applications: http://msdn.microsoft.com/en-us/library/ms412929(v=office.14).aspx )
- If you retract/deploy the solution which marked as “DeploymentServerType = ApplicationServer” then the application will never stopped or recycle.
- If you retract the solution which marked as “DeploymentServerType = WebFrontEnd” from SharePoint then SharePoint will first stop all the application pools and then start then one by one
- If we upgrade the solution which marked as “DeploymentServerType = WebFrontEnd” from SharePoint then SharePoint will first stop all the application pool and then start then one by one
- If we deploy the solution to SharePoint with -force then SharePoint then SharePoint will first stop all the application pool and then start then one by one
- If we deploy the solution to SharePoint without –force (or in the central admin) then SharePoint will recycle the application at the end of the progress
- If we deploy the solution to SharePoint without –force (or in the central admin) and “ResetWebServer = false” then SharePoint will not recycle the application pool any more. But to make your new solution works you need to recycle the application pool manually.
Then in your scenario if you want to reduce the downtime please do the following:
- Make sure you are using the right “DeploymentServerType” value to avoid the unnecessary restart on the application server
- Avoid to retract/upgrade the solution with “DeploymentServerType = WebFrontEnd” in the business time. As this scenario which stops all the application pool and start them again
- Deploy the solution without –force (or in the central admin) SharePoint will recycle them rather than stop and start them again
- Deploy the solution without –force and “ResetWebServer = false” in the solution manifest file will make the application pool with no recycle. But you need to recycle the application by yourself accordingly. Be sure that this has to be done manually, because Visual Studio creates for you the Manifest file.
Conclusion Solution Update
The deployment process on each front-end Web server involves copying files into system directories, installing features, and adding assembly DLLs to the GAC. Furthermore, SharePoint always runs a command to restart all the IIS worker processes that might be affected by the new components that have just been installed. For this reason, in production environments you should deploy solution packages during off hours with the provided gotchas when the fewest number of users are using the system.
Conclusion Infrastructure Upgrade
Let me quote Joel Spolsky:
Really high availability becomes extremely costly. The proverbial “six nines” availability (99.9999% uptime) means no more than 30 seconds downtime per year. That’s really kind of ridiculous. Even the people who claim that they have built some big multi-million dollar super-duper ultra-redundant six nines system are going to wake up one day, I don’t know when, but they will, and something completely unusual will have gone wrong in a completely unexpected way, three EMP bombs, one at each data center, and they’ll smack their heads and have fourteen days of outage.
Think of it this way: If your six nines system goes down mysteriously just once and it takes you an hour to figure out the cause and fix it, well, you’ve just blown your downtime budget for the next century. Even the most notoriously reliable systems, like AT&T’s long distance service, have had long outages (six hours in 1991) which put them at a rather embarrassing three nines … and AT&T’s long distance service is considered “carrier grade,” the gold standard for uptime.

 About the author: Gokan is an independent SharePoint Infrastructure consultant for @Neoxy where he assists clients with the design, implementation, maintenance, documentation, operations, configuration, administration and troubleshooting of their new or existing environments with PosH. His background offers half a decade of experience in providing IT solutions to clients in a wide variety of industries using Microsoft SharePoint technologies.
About the author: Gokan is an independent SharePoint Infrastructure consultant for @Neoxy where he assists clients with the design, implementation, maintenance, documentation, operations, configuration, administration and troubleshooting of their new or existing environments with PosH. His background offers half a decade of experience in providing IT solutions to clients in a wide variety of industries using Microsoft SharePoint technologies.
Gokan has successfully managed and designed a multiform infrastructure for up to 7500 users and maintains an active speaking schedule, addressing conferences in the Europe and MEA region.
He has additionally presented numerous conferences and is actively involved in the European and Dutch/French speaking communities: TechDays France, SharePoint Saturday (Paris, Belgium, Jersey, UK, Cairo, U.A.E), SQL Saturdays (Istanbul, Paris), Conf’SharePoint, SQL Pass, SPBiz, SP24, SharePoint Days Casablanca, JSS2014, CollabUEE, Office 365 Saturday, Rebuild, SharePoint Conference Ukraine … are a few of the major conferences.
Gokan is a proud author of 4 TN Wiki eBooks that reached the half million of downloads. Due to his active contributions in these domains, he has been honored with Microsoft’s Most Valuable Professional (MVP) award (2013-…). Additionally, he is an active Microsoft Certified Trainer (MCT) and a former Microsoft Community Contributor (MCC) (2011-2013).
You can reach Gokan on his blog (http://www.gokan.ms) and follow him on Twitter @gokanozcifci