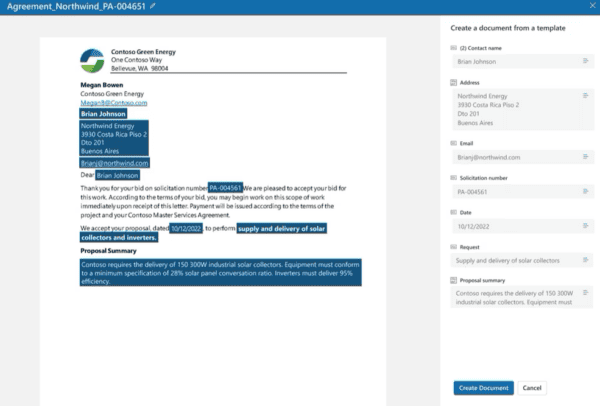
I was trying to figure out a way to get the text representation of documents stored either in OneDrive or SharePoint Online to execute some text analysis techniques using Azure machine learning studio. I know for sure (not really just guessing) that SharePoint search index store text representation of the document but I guess this version of the document is not exposed to us
Hmm #CognitiveServices can now tell you if text has profanity or derogatory terms.https://t.co/2dumIM2dkR
Waiting on @onedrive #ContentServices to return docx as txt then it'd be two @MicrosoftFlow actions.
Make a great O365 scanner that would flag docs to follow up
— John Liu 劉 (@johnnliu) March 28, 2018

using System.Linq;
using System.IO;
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Extensions.Http;
using Microsoft.Azure.WebJobs.Host;
using TikaOnDotNet.TextExtraction;
namespace doc2text
{
public static class Convert
{
[FunctionName("Convert")]
public static async Task<HttpResponseMessage> Run([HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = null)]HttpRequestMessage req, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
byte[] data = await req.Content.ReadAsByteArrayAsync();
var textExtractor = new TextExtractor();
return req.CreateResponse(HttpStatusCode.OK, textExtractor.Extract(data).Text);
}
}
}
The flow will start then it will trigger the azure function which will extract the text representation of the office document and send it to a web-service to do some text analysis and return the document classification value.
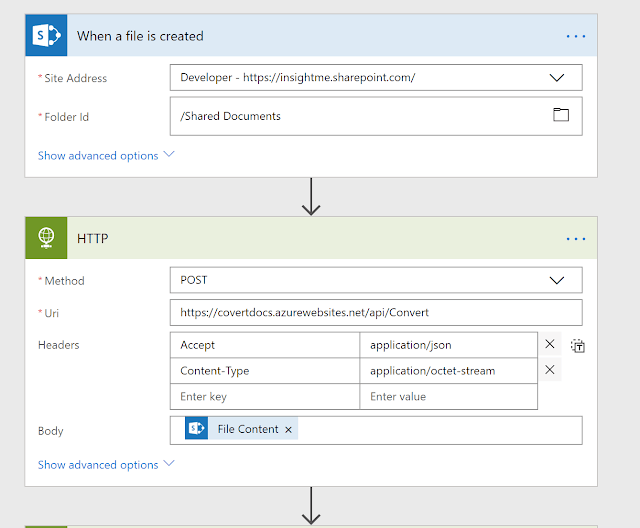
File Content
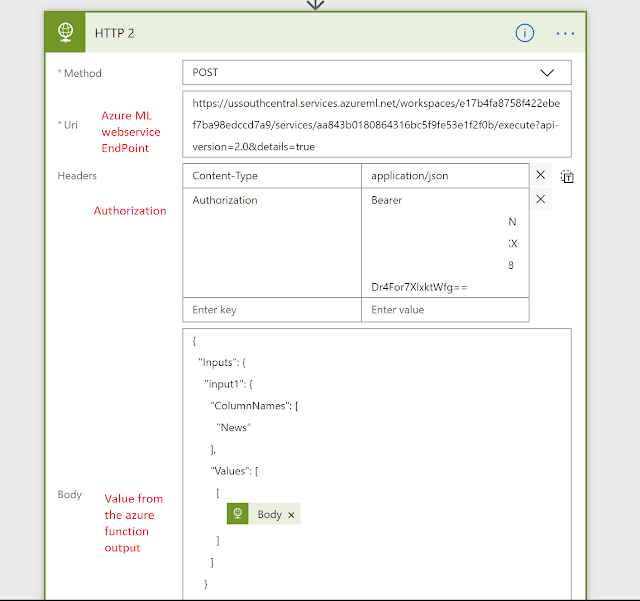
Method: Post
Then within the flow itself we can update the SharePoint document and update the classification as per the text analysis result.
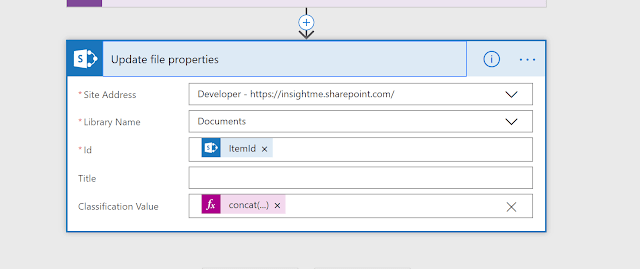
File properties
now let’s upload a new word document that have a text represents a business article and let’s see the updated category text value
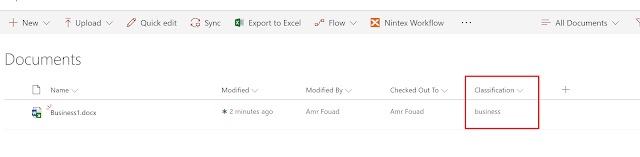
Classifications – Business