In the scope of this article I will be using the term Data Architecture to refer to the use cases where enterprises plan to bring together data from various transactional stores for analytical needs like Business Intelligence, Reporting and Machine Learning source for Data Scientists. Data Architecture can consist of Data Lake, Data Warehouse or a combination of both. I am a firm believer that “One size doesn’t fit all” so it’s very nice to have a variety of options available in Azure but at the same time it can be daunting to see so many choices and decision points. In this blog post I will share some reference architectures, try to highlight which components fit where and why one would prefer one over the other.
Note: I would not classify this article as introductory, you will gain the most if have conceptual understanding of Data Lake, Data Warehouses, where Apache Spark fits in the Big Data world, etc. and trying to figure out architecture on Azure Cloud Platform.
Table of Contents
- Azure Synapse Basics
- Data Lake or Data Warehouse — Do I need one or combination of both?
- Data Warehouse Pattern
- Data Lake Pattern
- 2 Tiers — Data Lake with Data Warehouse
- SQL DB Flavors instead of Azure Synapse for smaller Datasets
Azure Synapse Basics
Azure Synapse is a very broad and key service to understand when building data architecture on Azure. The public documentation defines Azure Synapse as “a limitless analytics service that brings together enterprise data warehousing and Big Data analytics”. I will start off by highlighting a few components relevant to the scope of this article but there is much more which can read about in public documentation. Please feel free to skip this section if you are already familiar with it.
Azure Synapse is a composite service and following are the key components under Azure Synapse umbrella which I would like to highlight for the conversation here:
- Synapse SQL Dedicated Pool (formerly referred to as SQL Data Warehouse) — T-SQL based database, follows MPP architecture similar to Netezza, Teradata, etc. Synapse SQL Dedicated Pool is charged an hourly rate based on DWU (unit of scale), you can scale it up or down or even pause it so storage and compute are not tightly coupled.
- Synapse SQL Serverless Pool — T-SQL based engine to query data sitting in Azure Storage, uses pay per query model (amount of data processed per query) rather than hourly rate.
- Synapse Spark — Spark Engine where you prefer using Apache Spark well-known tool for big data analytics.
- Synapse Pipelines — This is Azure Data Factory (ADF) integrated into Azure Synapse Workspace for better user experience, this is categorized as Data Integration in documentation and can be used for building data pipelines for the orchestration needs (at the time of writing this article there are difference between standalone ADF and Synapse Pipelines which are documented here).
Azure Synapse aims to provide a nice integrated experience for data ingestion, processing and consumption needs without requiring you to glue together separate services. As you go through the architectures below do keep in mind that selecting options within Azure Synapse is considered a plus with the idea that it gives more streamlined and integrated experience for users reducing the friction in getting started.
Data Lake or Data Warehouse — Do I need one or combination of both?
When starting off the common question is whether to build out a Data Warehouse or a Data Lake, please check out this very detailed article Data Lakehouse defined, at this point in time I am of the opinion you will most likely need two-tier solution with data lake + relational data warehouse and not just one or the other. Regardless of what direction you decide on there are multiple choices in Azure Platform to support your implementation and the following section shows few reference architectures as well reasonings for selecting a particular technology. In my opinion skill set and cost play a big role in decision making.
Relevant Links:
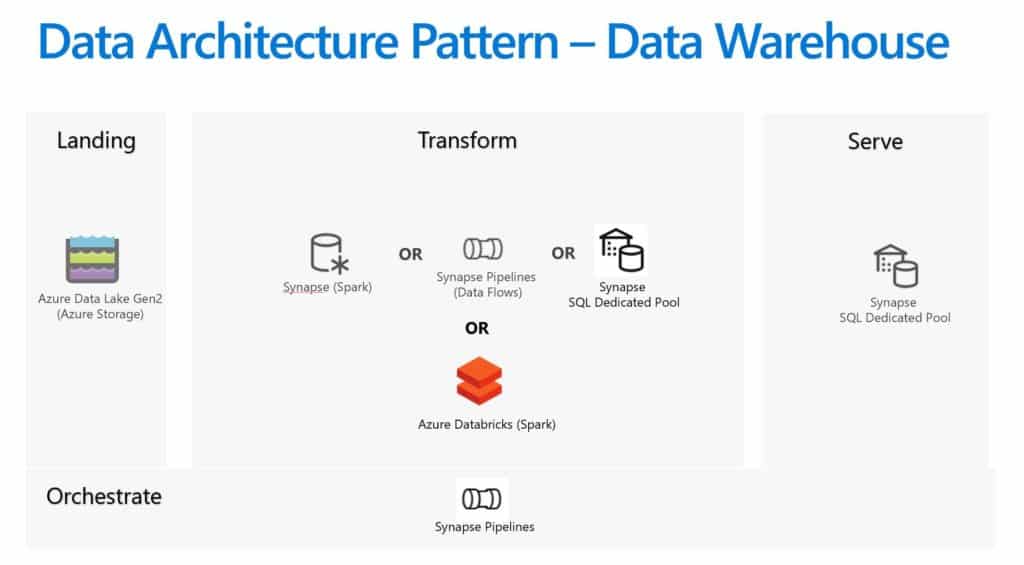
Data Warehouse Pattern
Simple more traditional pattern where data is loaded into Synapse SQL Dedicated Pool tables (can be referred to as Synapse SQL Dedicated Pool Managed Tables) for consumption. One important thing to call out here is that it would be incorrect to label Synapse SQL Dedicated Pool as tight coupling of Compute and Storage, you can scale Synapse SQL Dedicated Pool instance up and down or even pause it without losing the data in the managed tables. Also, Synapse SQL Dedicated Pool can directly query data sitting in Azure Storage as External Tables though the performance of query is expected to be much slower in comparison to managed tables hence external table method is generally considered for data exploration or less frequent ad-hoc analysis (external tables shown in subsequent sections for Data Lake and 2 tier Data Lake and Data Warehouse patterns).

Relevant Links:
- Differences between Synapse Spark and Azure Databricks Spark — Nice article might but it might be outdated Spark 3.01 is available in Preview for Synapse Spark starting May 2021
- Synapse SQL Dedicated Pool — DWU Unit of Scale
Data Lake Pattern
Azure Storage (Data Lake Gen2 to be specific) is the service to house the data lake, Storage doesn’t have any compute so a Serving compute layer is needed to read data out of Storage. When going with the Data Lake pattern one very important aspect to plan for is how to handle updates and deletes for the data saved in Data Lake as Data Lakes are not very conducive to updates and deletes. Delta Lake format which is an enhancement over Parquet provides transaction layer over Data Lakes and enables that update/delete functionality. It’s important to keep in mind that Delta Format for Data Lake is still an Analytical Store and not an OLTP system so not a good idea to overuse the update/delete functionality. Delta Lake format has lots other benefits as well, see the Delta Lake docs to learn more.
One common reason to consider Data Lake Pattern is that it might be more cost effective but as things are evolving you might want to do a deeper analysis to estimate true cost effectiveness of the solution, the cost of data stored inside Azure Synapse SQL Dedicated Pool was dropped by 80% in December of 2020 to $23 per TB (as always refer to the Pricing page for most up to date pricing information).
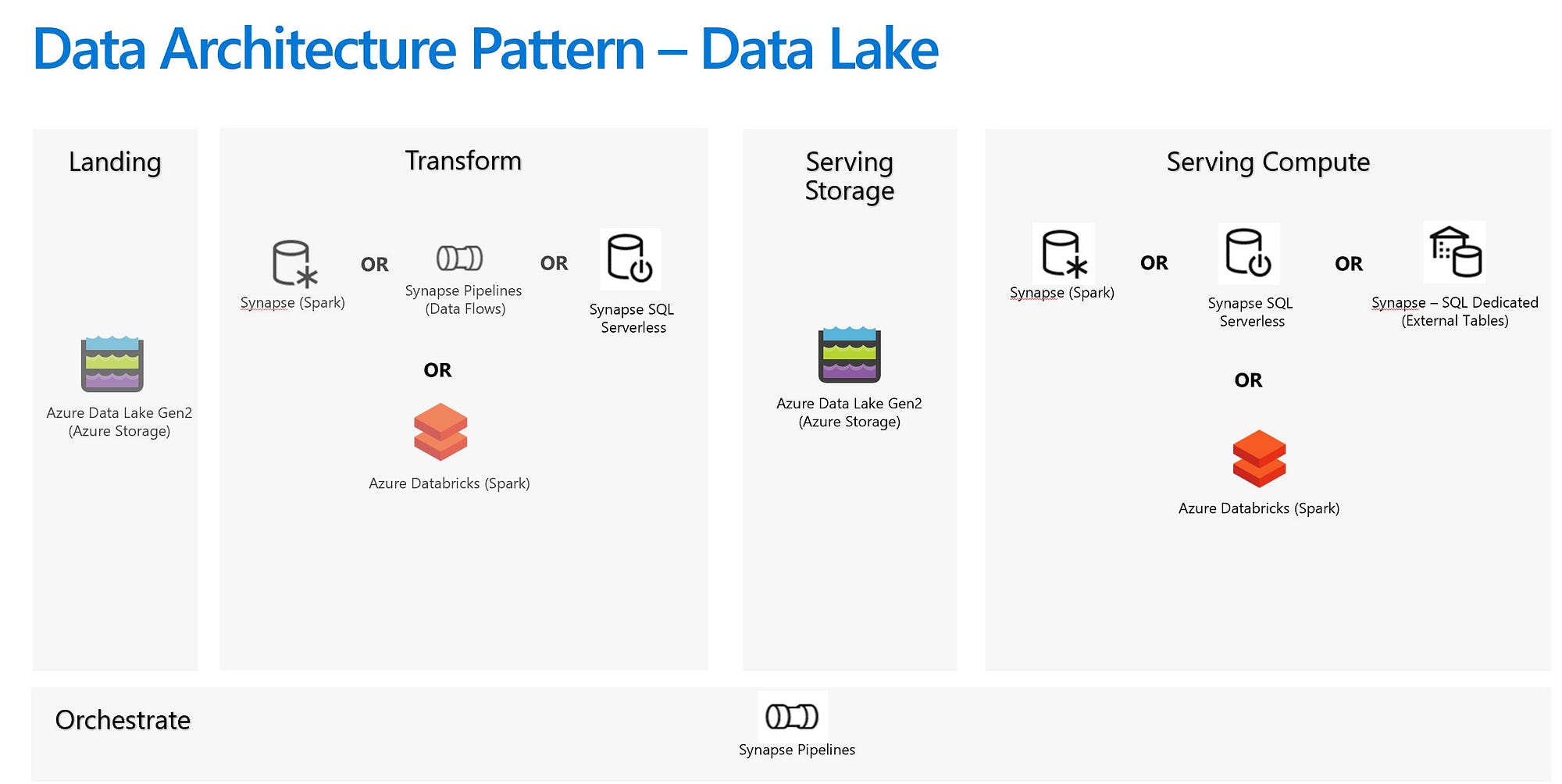
Transform Layer Choices
Everything listed under Data Warehouse section still holds true, only new addition here is Synapse SQL Serverless
Synapse SQL Serverless
- T-SQL Stored Procedures can be used to transform data in Azure Storage, link to tutorial on how to use Synapse SQL Serverless to transform using Storage Procedure — https://docs.microsoft.com/en-us/learn/modules/use-azure-synapse-serverless-sql-pools-for-transforming-data-lake/
- Pay per use (per TB of data processed) cost model
- Reading of Delta Lake format is supported starting May 2021

Please checkout the link for documentation on Azure Databricks BI Tool Connectivity , the list is pretty elaborate including Tableau, JDBC, ODBC, etc.
2 Tier — Data Lake with Data Warehouse
I believe most likely you will end up using this pattern where you use best of both worlds:
- Data Lake is for quick ingestion with schema on read, cost effective for extremely large datasets, it enables experimentation and ad-hoc analysis at a lower cost but transformed subsets need to be loaded to relational engine like Synapse SQL Dedicated Pool for low latency and higher concurrency requirements like reporting dashboards (MPP engines like SQL Dedicated Pool have concurrency constraints as well but usually recommended over Apache Spark). I highly recommend reading the article Data Lakehouse defined.
- Its more common to use Data Lake with Machine Learning use cases because you already have compute engine (e.g. Spark) separate from relational database compute engine where you run your Machine Learning code and you can rely on that compute engine to read from data lake
- The beauty of Azure Synapse is that it doesn’t lock you into as single technology and you have variety of tools to access the data and let your consumers choice based on their skillset and use case
- Row and Column Level Security is harder to implement on the Data Lake and comes out of the box with Synapse SQL Dedicated Pool
Following diagram showcases this hybrid architecture with Azure Synapse, you can build similar architecture with Databricks as well if you like.


SQL DB Flavors instead of Azure Synapse for smaller Datasets
I have kept the scope of this article limited to larger datasets (say more than at least 1 TB) and focused more on the Azure Synapse but if your dataset is on lower end then you can consider an alternate architecture with Azure SQL which is SMP instead of Azure Synapse SQL Dedicated Pool. Azure has many flavors of SMP SQL :
- SQL in VM (IaaS rather PaaS)
- Azure SQL (4 TB Limit) – Azure SQL Hyperscale SKU which goes up to 100 TB, or
- Azure SQL Managed Instance (8 TB Limit).
These flavors of SQL are not commonly seen in Data Warehouse Architecture diagrams but in my opinion they are fine options to consider if data volume is on the lower end and you prefer sticking with SMP rather than MPP, data load times are expected to be higher in SMP in comparison to MPP (loads in Synapse SQL Dedicated Pool are performed in parallel using specialized Polybase or COPY command). Another reason to consider SMP flavor of SQL is skillset (best practices and patterns are different for MPP). If going with Azure SQL, you would be losing that integrated Synapse Workspace experience so at that point it might make sense to consider Azure Data Factory instead of Azure Synapse Pipelines.

IF you are using Synapse, you might want to use stand along Azure Data Factory, differences are documented here.
Disclaimer: Things change fast in the world of technology, I will try my best to keep this article up to date. Also, this is my personal view based on my learnings and how I see different pieces of technology on this very broad Azure Platform
About the Author:
Senior Cloud Architect @Microsoft. Please feel free to connect with me on LinkedIn: https://www.linkedin.com/in/singhinderjit/

Rna, I. (2021). Data Lake or Data Warehouse or a Combination of Both — Choices in Azure and Azure Synapse. Available at: https://medium.com/microsoftazure/data-lake-or-data-warehouse-or-a-combination-of-both-choices-in-azure-and-azure-synapse-6b99cd072f99 [Accessed: 8th July 2021].