The first mistake that all new Analysis Services Tabular developers make is this one: they create a new project in SSDT, they connect to their source database, they select the tables they want to work with, they click Import, and they then realise that trying to load a fact table with several million rows of data into their Workspace Database (whether that’s a separate Workspace Database instance or an Integrated Workspace) is not a good idea when they either end up waiting for several hours or SSDT crashes because it has run out of memory. You of course need to filter your data down to a manageable size before you start developing in SSDT. Traditionally, this has been done at the database level, for example using views, but modern data sources in SSAS 2017 and Azure Analysis Services allow for a new approach using M.
Here’s a simple example of how to do this using the Adventure Works DW database. Imagine you are developing a Tabular model and you have just connected to the relational database, clicked on the FactInternetSales table and clicked Edit to open the Query Editor window before importing. You’ll see something like this:
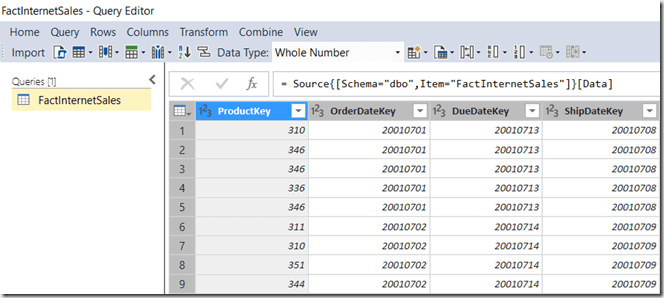
Query Editor
…that’s to say there’ll be a single query visible in the Query Editor with the same name as your source table. The M code visible in the Advanced Editor will be something like this:
let
Source =
#"SQL/localhost;Adventure Works DW",
dbo_FactInternetSales =
Source{[Schema="dbo",Item="FactInternetSales"]}[Data]
in
dbo_FactInternetSales
- Filter the data down to a much smaller number of rows for the Workspace Database
- Load all the data in the table after the database has been deployed to the development server
To do this, stay in the Query Editor and create a new Parameter by going to the menu at the top of the Query Editor and clicking Query/Parameters/New Parameter, and creating a new parameter called FilterRows of type Decimal Number with a Current Value of 10:
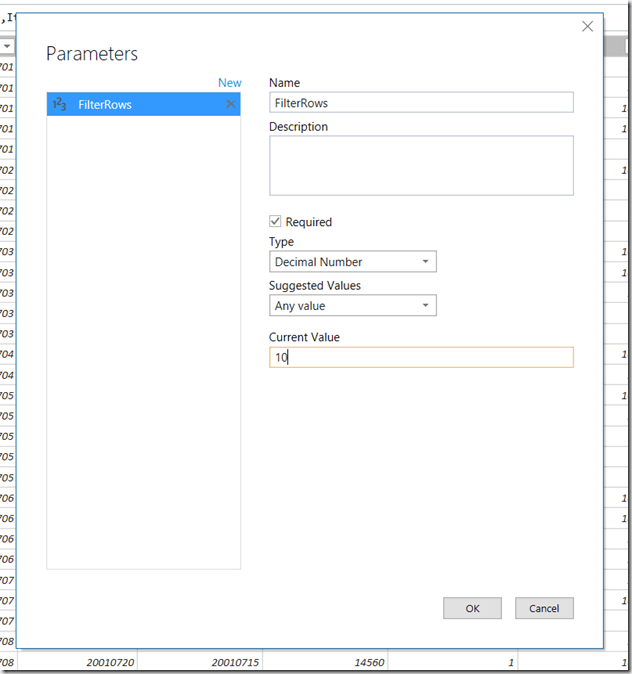
Parameters
The parameter will now show up as a new query in the Queries pane on the left of the screen:
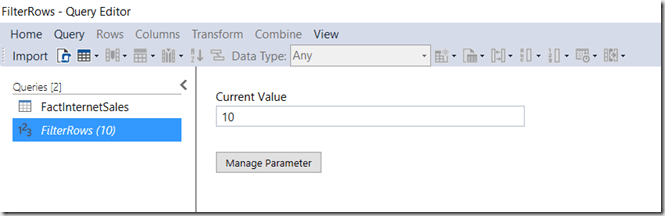
Filter Rows Query Editor
Note that at the time of writing there is a bug in the Query Editor in SSDT that means that when you create a parameter, close the Query Editor, then reopen it, the parameter is no longer recognised as a parameter – it is shown as a regular query that returns a single value with some metadata attached. Hopefully this will be fixed soon but it it’s not a massive problem for this approach.
Anyway, with the parameter created you can now use the number that it returns to filter the rows in your table. You could, for example, decide to implement the following logic:
- If the parameter returns 0, load all the data in the table
- If the parameter returns a value larger than 0, interpret that as the number of rows to import from the table
Here’s the updated M code from the FactInternetSales query above to show how to do this:
let
Source =
#"SQL/localhost;Adventure Works DW",
dbo_FactInternetSales =
Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
FilterLogic =
if
FilterRows<=0
then
dbo_FactInternetSales
else
Table.FirstN(dbo_FactInternetSales, FilterRows)
in
FilterLogic
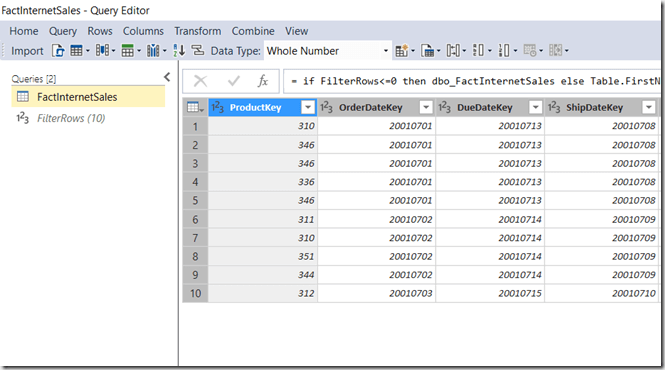
FactInternetSales
And yes, query folding does take place for this query.

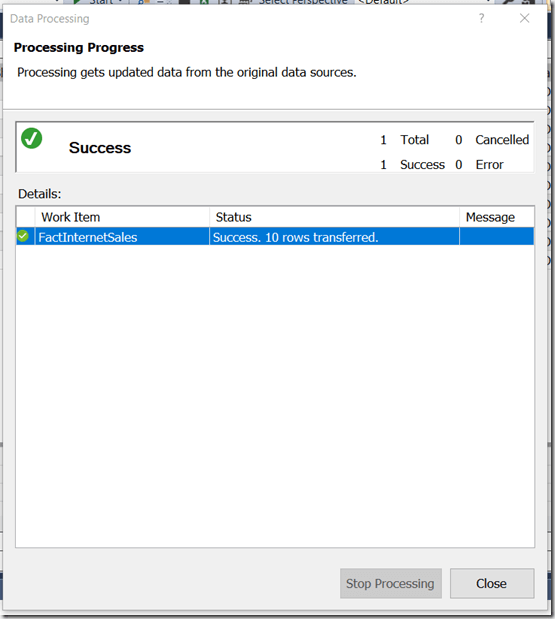
Data Processing
What happens when you need to deploy to development though?
First, edit the FilterRows parameter so that it returns the value 0. To do this, in the Tabular Model Explorer window, right-click on the Expressions folder (parameters are classed as Expressions, ie queries whose output is not loaded into Analysis Services) and select Edit Expressions:
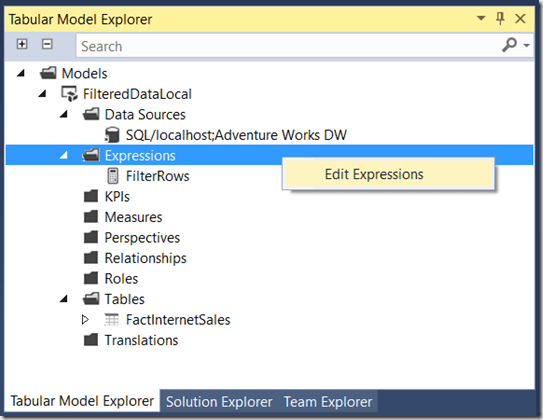
Tabular Model Explorer
Once the bug I mentioned above has been fixed it should be easy to edit the value that the parameter returns in the Manage Parameters pane; for now you need to open the Advanced Editor window by clicking the button shown below on the toolbar, and then edit the value in the M code directly:
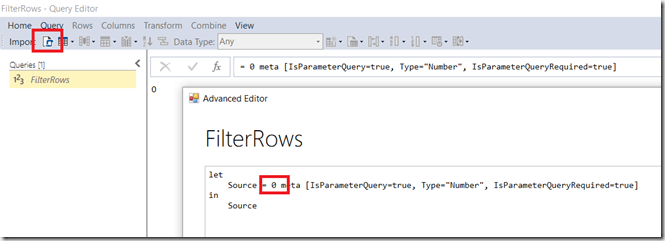
Filter Rows
Then close the Advanced Editor and click Import. Nothing will happen now – the data for FactInternetSales stays filtered until you manually trigger a refresh in SSDT – and you can deploy to your development server as usual. When you do this, all of the data will be loaded from the source table into your development database:
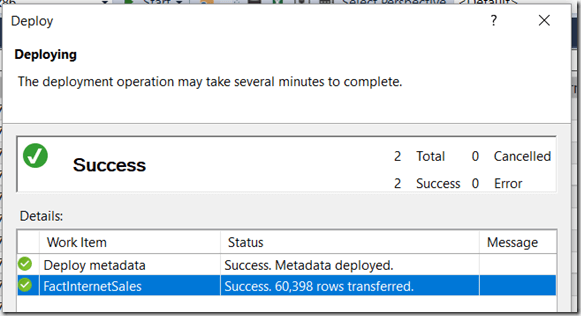
Depioying
At this point you should go back to the Query Editor and edit the FilterRows parameter so that it returns its original value, so that you don’t accidentally load the full dataset next time you process the data in your Workspace Database.
It would be a pain to have to change the parameter value every time you wanted to deploy, however, and luckily you don’t have to do this if you use BISM Normalizer – a free tool that all serious SSAS Tabular developers should have installed. One of its many features is the ability to do partial deployments, and if you create a new Tabular Model Comparison (see here for detailed instructions on how to do this) it will show the differences between the project and the version of the database on your development server. One of the differences it will pick up is the difference between the value of the parameter in the project and on in the development database, and you can opt to Skip updating the parameter value when you do a deployment from BISM Normalizer:
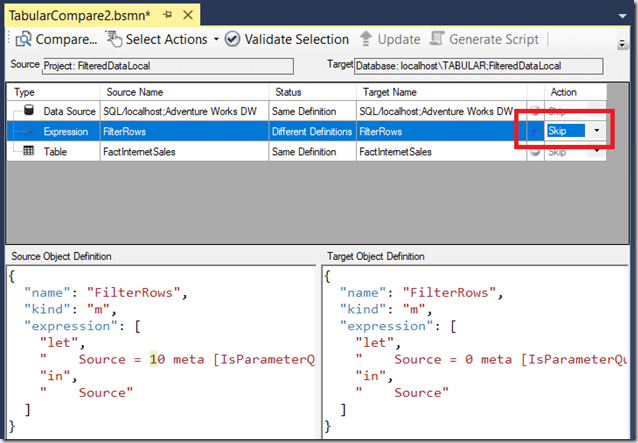
TabularCompare2
Reference:
Webb, C. (2018). Filtering Data Loaded Into A WorkSpace Database In Analysis Services Tabular 2017 And Azure Analysis Services. [online] Available at: https:/https://blog.crossjoin.co.uk/2018/02/26/filtering-data-loaded-into-a-workspace-database-in-analysis-services-tabular-2017-and-azure-analysis-services//codecraft.tv/blog/2017/09/07/angularjs-to-angular-using-iframes/ [Accessed 22 Mar. 2018].