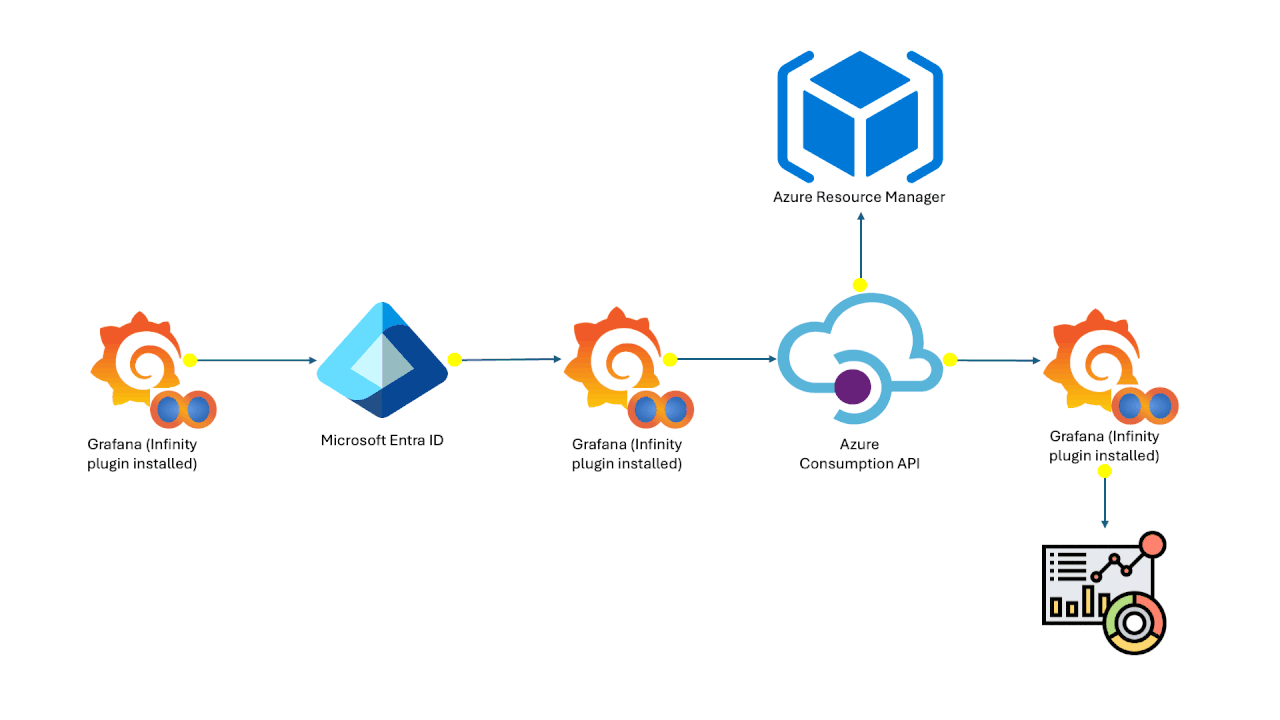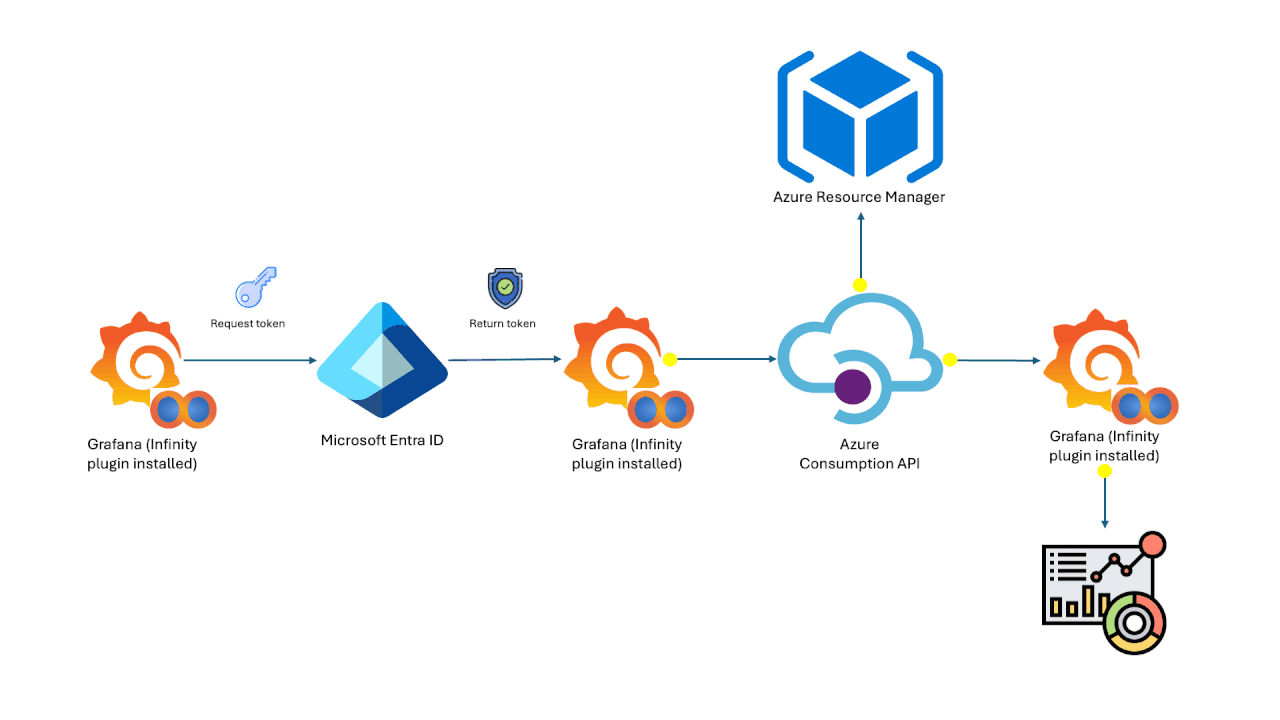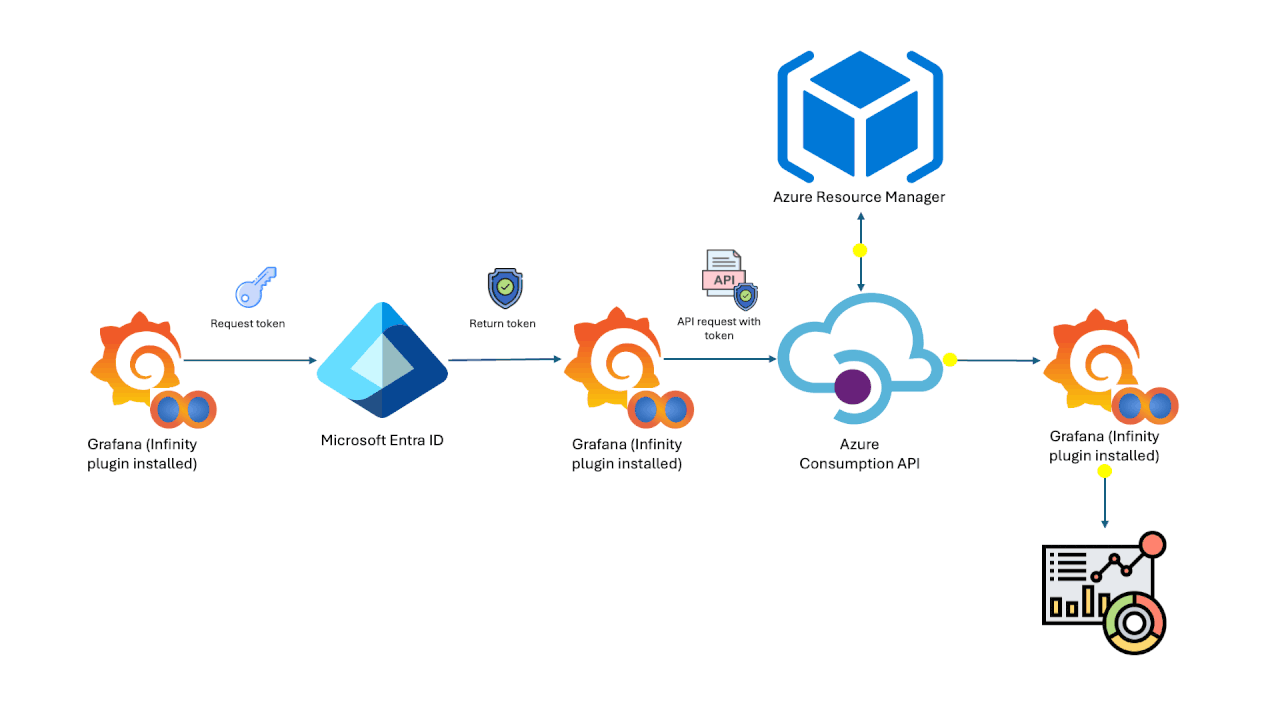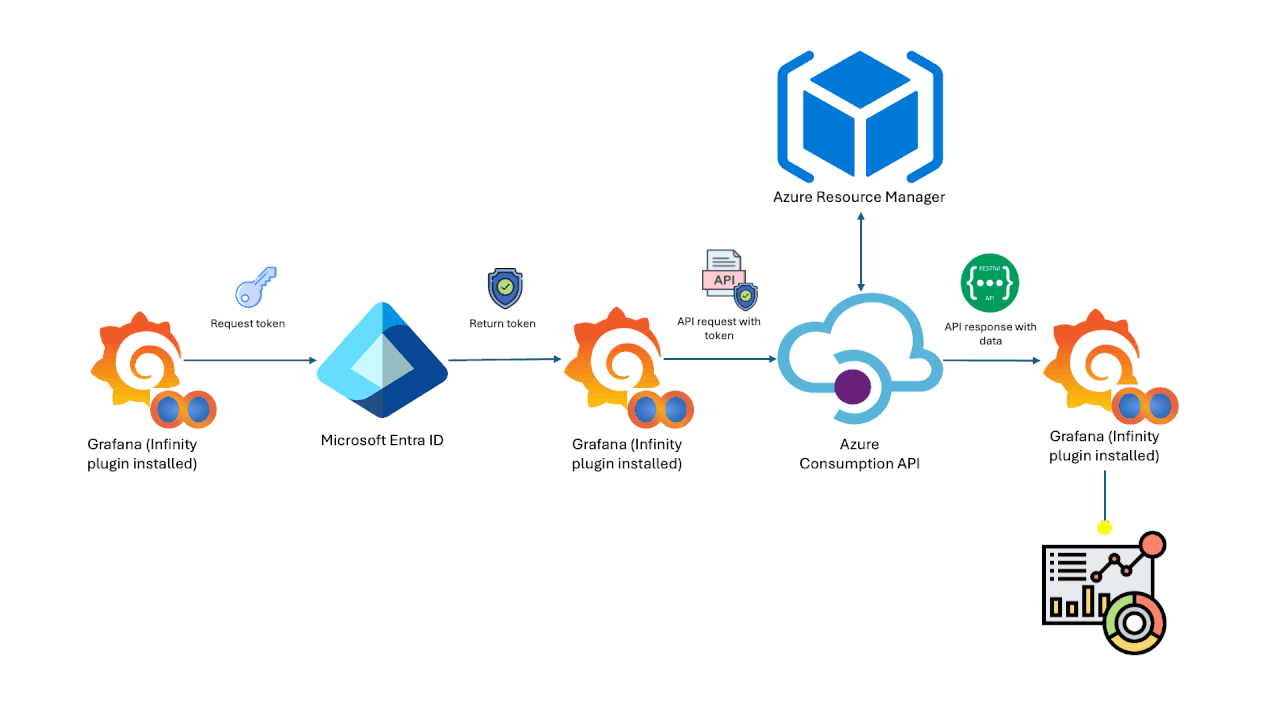
DataStores
In Azure ML, datastores are references to storage locations, such as Azure Storage blob containers. Every workspace has a default datastore – usually the Azure storage blob container that was created with the workspace.
When data is uploaded into the datastore through the following code
default_ds.upload_files(files=['data/diabetes.csv', 'data/diabetes2.csv'], # Upload the diabetes csv files in /data
target_path='diabetes-data/', # Put it in a folder path in the datastore
overwrite=True, # Replace existing files of the same name
show_progress=True)
we can see the files in the Azure Storage Account > Containers > Blob Stores
Datasets
While we can read data directly from
datastores, Azure Machine Learning provides a further abstraction for data in the form ofdatasets.
A dataset is a versioned reference to a specific set of data that we may want to use in an experiment.
Datasets can be tabular or file-based.

Create the workspace
import azureml.core
from azureml.core import Workspace
from azureml.core.authentication import InteractiveLoginAuthentication
sid = '<your-subscription-id>'
forced_interactive_auth = InteractiveLoginAuthentication(tenant_id="<your-tenant-id>", force=True)
ws = Workspace.create(name='azureml_workspace',
subscription_id= sid,
resource_group='rgazureml',
create_resource_group = True,
location='centralus'
)
Upload the Data into the default data store
#upload data by using get_default_datastore()
ds = ws.get_default_datastore()
ds.upload(src_dir='./winedata', target_path='winedata', overwrite=True, show_progress=True)
print('Done')
Create a Tabular Dataset
from azureml.core import Dataset
csv_paths = [(ds, 'winedata/winequality_red.csv')]
tab_ds = Dataset.Tabular.from_delimited_files(path=csv_paths)
tab_ds = tab_ds.register(workspace=ws, name='csv_table',create_new_version=True)
Create the folder for the code
import os
# create the folder
folder_training_script = './winecode'
os.makedirs(folder_training_script, exist_ok=True)
print('Done')
Create the Compute Target
from azureml.core.compute import AmlCompute
from azureml.core.compute import ComputeTarget
import os
# Step 1: name the cluster and set the minimal and maximal number of nodes
compute_name = os.environ.get("AML_COMPUTE_CLUSTER_NAME", "cpucluster")
min_nodes = os.environ.get("AML_COMPUTE_CLUSTER_MIN_NODES", 0)
max_nodes = os.environ.get("AML_COMPUTE_CLUSTER_MAX_NODES", 1)
# Step 2: choose environment variables
vm_size = os.environ.get("AML_COMPUTE_CLUSTER_SKU", "STANDARD_D2_V2")
provisioning_config = AmlCompute.provisioning_configuration(
vm_size = vm_size, min_nodes = min_nodes, max_nodes = max_nodes)
# create the cluster
compute_target = ComputeTarget.create(ws, compute_name, provisioning_config)
print('Compute target created')
Create the Training script
%%writefile $folder_training_script/train.py
import argparse
import os
import numpy as np
import pandas as pd
import glob
from azureml.core import Run
from azureml.core import Dataset
# from utils import load_data
import joblib
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import cross_val_score
# let user feed in 2 parameters, the dataset to mount or download, and the regularization rate of the logistic regression model
parser = argparse.ArgumentParser()
parser.add_argument('--input-data', type=str, dest='training_dataset_id', help='data folder mounting point')
parser.add_argument('--max-depth', type=float, dest='max_depth', default=5, help='max depth')
args = parser.parse_args()
###
run = Run.get_context()
ws = run.experiment.workspace
dataset = Dataset.get_by_id(ws, id=args.training_dataset_id)
wine_data = dataset.to_pandas_dataframe()
wine_data = wine_data.dropna()
X = wine_data.drop(columns =["quality"])
y = wine_data["quality"]
clf = DecisionTreeRegressor(random_state=0,max_depth = args.max_depth)
rmse= np.mean(np.sqrt(-cross_val_score(clf, X, y, scoring="neg_mean_squared_error", cv = 5)))
print('RMSE is', rmse)
# Get the experiment run context
run = Run.get_context()
run.log('max depth', np.float(args.max_depth))
run.log('rmse', np.float(rmse))
os.makedirs('outputs', exist_ok=True)
clf.fit(X,y)
# note file saved in the outputs folder is automatically uploaded into experiment record
joblib.dump(value=clf, filename='outputs/wine_model.pkl')
run.complete()
Create the Environment
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
# Create a Python environment for the experiment
wine_env = Environment("wine-experiment-env")
wine_env.python.user_managed_dependencies = False # Let Azure ML manage dependencies
wine_env.docker.enabled = False # Use a docker container
# Create a set of package dependencies (conda or pip as required)
wine_packages = CondaDependencies.create(conda_packages=['scikit-learn'])
# Add the dependencies to the environment
wine_env.python.conda_dependencies = wine_packages
print(wine_env.name, 'defined.')
# Register the environment
wine_env.register(workspace=ws)
Create the Run Configuration
from azureml.core import Experiment, ScriptRunConfig, Environment
registered_env = Environment.get(ws, 'wine-experiment-env')
# Get a dataset from the workspace datasets collection
ds1 = ws.datasets['csv_table']
#Create a script config
script_config = ScriptRunConfig(source_directory=folder_training_script,
script='train.py',
arguments = ['--max-depth',10,
'--input-data', ds1.id], # Reference to dataset
environment=registered_env)
Create the Experiment and the Run
from azureml.core import Experiment
#Create an experiment
experiment = Experiment(workspace = ws, name = "wine_expt")
run = experiment.submit(config=script_config)
run
This blog is part of Azure Week. Check it out for more great content!
References
About the Author:
I am a Business and Technology Consultant for more than 20 Years. I am a data lover and compete regularly in data science competitions. I had won Eight Data Science Competition Awards ( 1 sponsored by NASA, Seven sponsored by Kaggle – A Google Company).
NASA has recognized me as a Citizen Scientist and has been extremely generous to have a page here
Reference:
Ganguly, A. (2021). Azure ML DataStores and Datasets. Available at: https://ambarishg.github.io/posts/2021-03-15-azure-ml-datastores-datasets-basics/ [Accessed: 8th July 2021].