In this article we will explain how to use Flow to extract multiple values from a PDF document & use them to populate a SharePoint List.
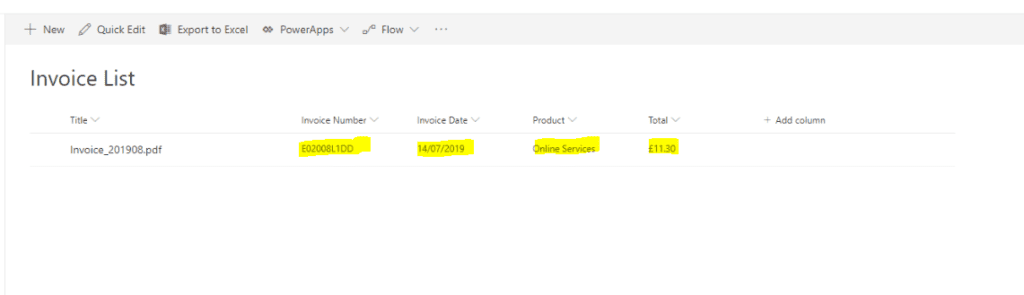
A common use case for this requirement is an “Invoice” document & in the example invoice below we want to extract the following information
- Invoice Number
- Invoice Date
- Product
- Total

In this example, we are going to Trigger the flow when an item gets created in SharePoint & then using the Aquaforest “Get Text from PDF” Connector, we will define the values that we wish to extract.
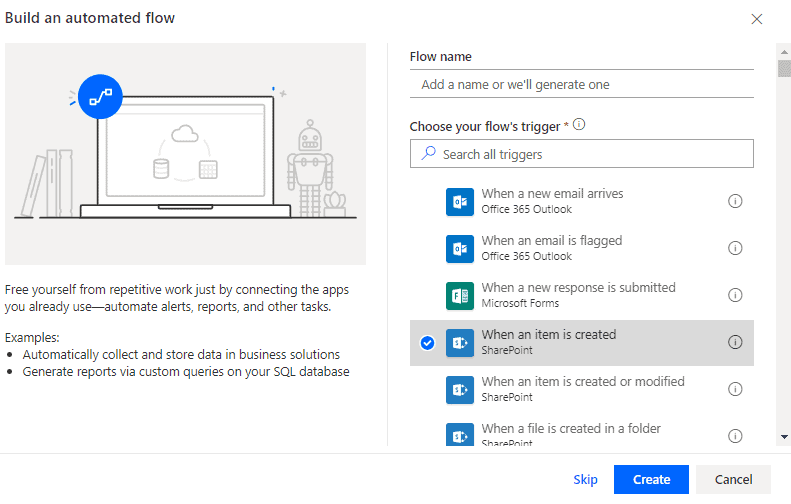
- Create a new Automated Flow, “When an item is
created”
- Specify the Location,
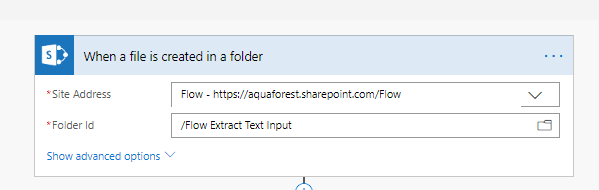
3. This step makes use of the Aquaforest PDF Connector which is free to use up to a certain number of actions. Specifically we then need to add the “Aquaforest: Get Text from PDF” action. More information about the connector can be found here : https://www.aquaforest.com/en/aquaforest-flow-doc.asp
4. We will start by defining the zones/locations on the page, where we wish to extract text from.
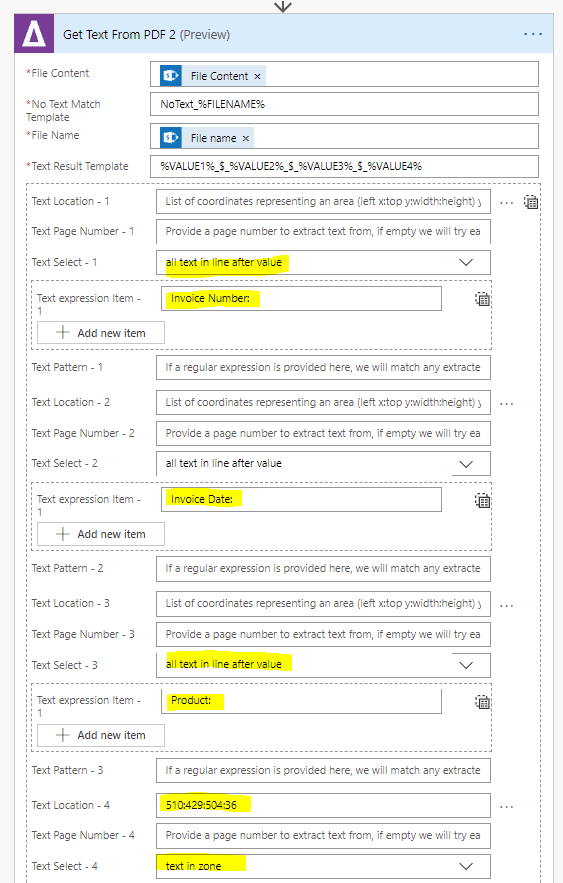
a. Three of the items on the page (Invoice Number, Invoice Date & Product) all have labels, so we can simply specify “all text in line after value” & the label, ie “Invoice Number” in the first example.
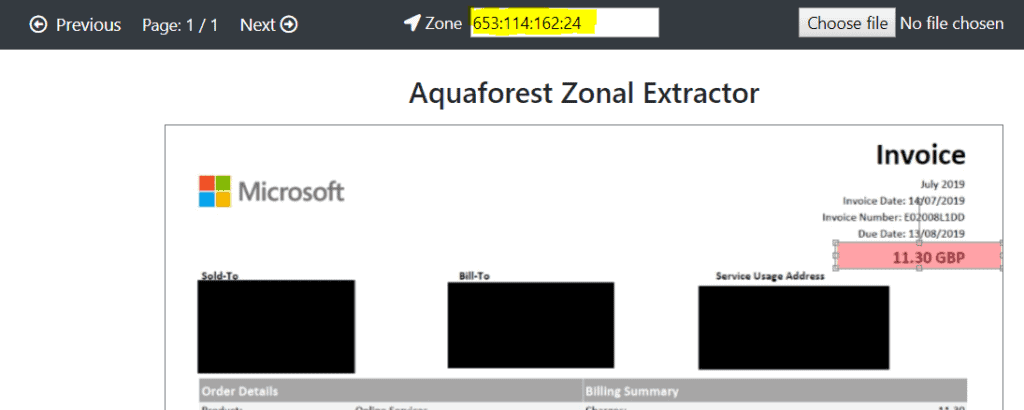
b. For final item, “Total” which doesn’t have a label, the only way to be sure of extracting the correct value is to define a zone. To defines the zones use our Kingfisher Zone Drawing Tool which can be found at the following URL: https://www.aquaforest.com/en/zone/get-pdf-zone.html
We load the document into the tool & then select each of the Zones in turn & this will provide the coordinates of each Zone.

So this is the “Text Result Template” %VALUE1%_$_%VALUE2%_$_%VALUE3%_$_%VALUE4%
( see attached screenshot).
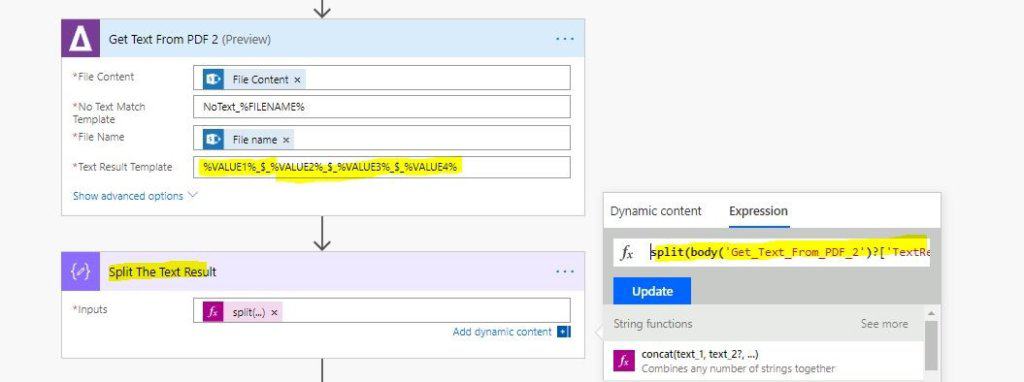
6. We then add a “Data Operation”, Step to (Split Text Results) with the following value: split(body(‘Get_Text_From_PDF_2’)?[‘TextResult’],’_$_’)
(see screenshot above).
7. When dealing with date fields & as explained in the article below converting strings to date/time data types is none trivial
https://threewill.com/how-to-convert-strings-datetime-data-types-microsoft-flow/
a. You need to break the date into its component parts (day, month, year) by using another “Data Operation” step named ( Split Date) with the following value: split(outputs(‘Split_The_Text_Result’)[1],’/’)
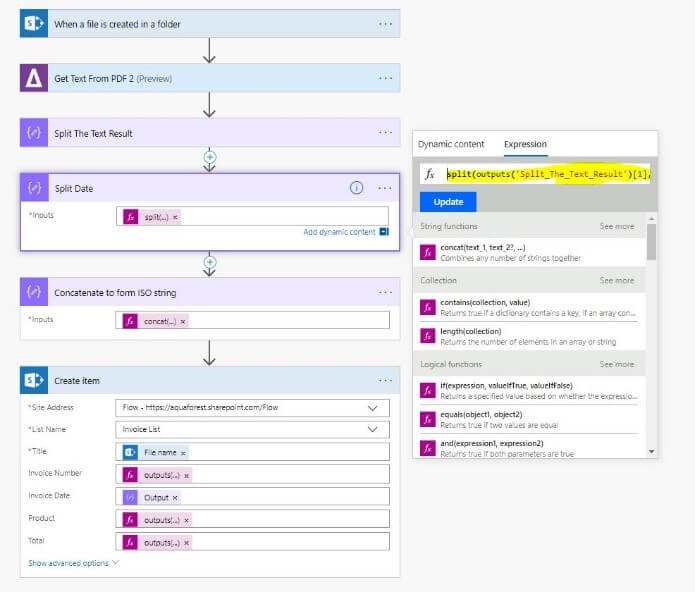
– This basically takes the results from the “Split Text Results” data operation, specify the item number & then find each of the values between the date delimiters “/”
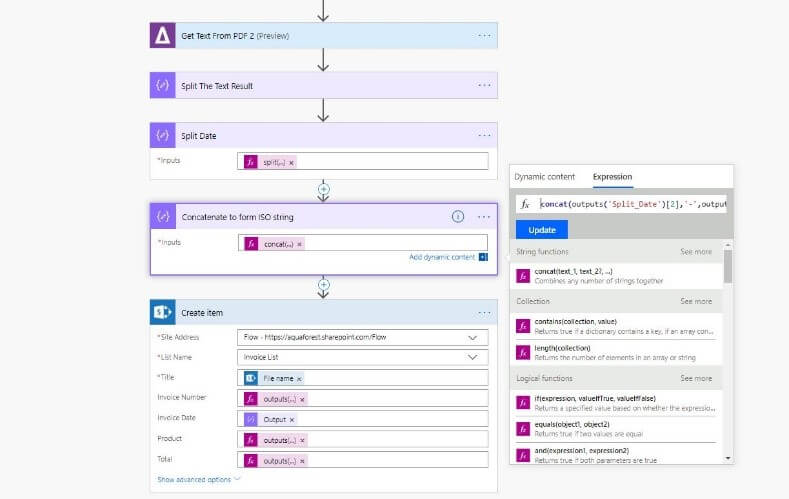
b. The second step is to form a valid ISO String & we do this with another “Data Operation” step named (Concatenate to form ISO string) with the following value : concat(outputs(‘Split_Date’)[2],’-‘,outputs(‘Split_Date’)[1],’-‘,outputs(‘Split_Date’)[0])
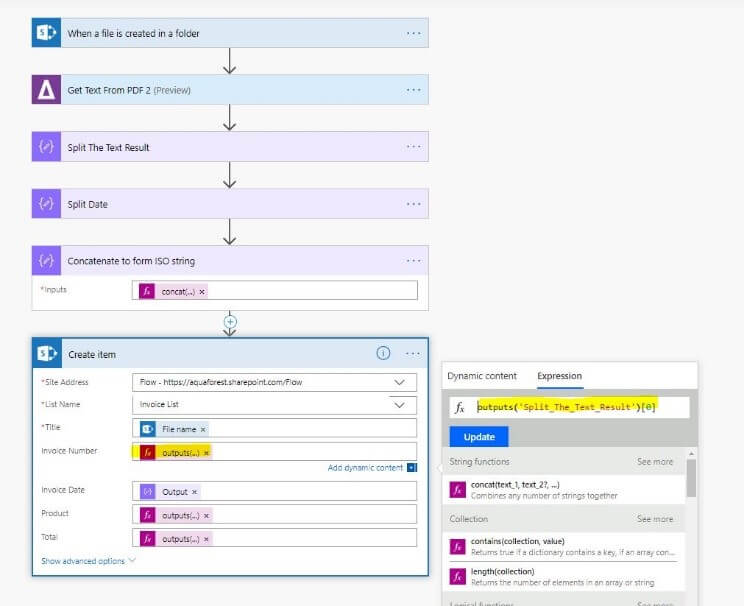
8. Then for your output, to specify which field names below to which values in the string you simply specify the following: outputs(‘Split_The_Text_Result’)[0]
With the number (0) in the example, denoting the position in the string for the value that you require.
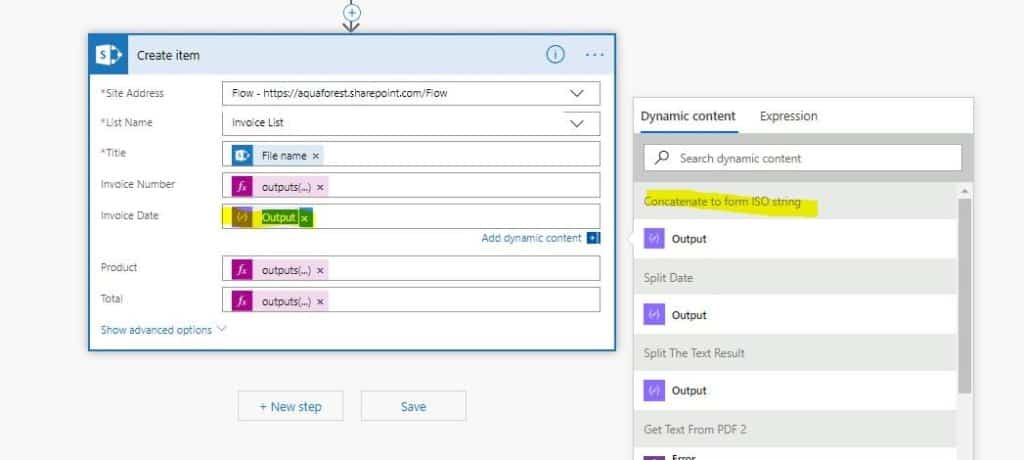
9. Then for the output of any date fields, you need to specify the “Output” from the “Concatenate to form ISO string” steps.
(see attached)
10. After Saving the Flow & Adding a document to the library, it has populated the Custom Metadata into our Custom Metadata Columns as per the screenshot below.
10. The output from the Aquaforest Get Text from PDF connector, currently returns a string, with all the values in it & we define this in the “Text Results Template” field. currently returns a string with the all values contained within it. In order to be able to retrieve the individual values, you need to parse the string to retrieve the individual values. To make this easier, it makes sense to define a delimiter (that you know won’t appear within your results). In this example, we have we have used _$_