Use the force to speed up your patch operations.

I recently flew out to the Dagobah system to catch up with my mate, Yoda. He told me that the Power Apps patch function is a powerful ally that surrounds and binds us. We must learn to harness its powers when it comes to creating or updating multiple rows in a data source.
In this article I’ll walk through the three methods he’s trained me to use, and include some nerdy analysis of which method is the quickest! Remember, a Jedi’s strength flows from Power Fx…
The Patch function
The Power Apps Patch function is primarily used to create or modify one or more records in a data source. This is likely to be your go-to Power Fx function when you’re not creating or editing a single row with an Edit form control.
The function works like so:
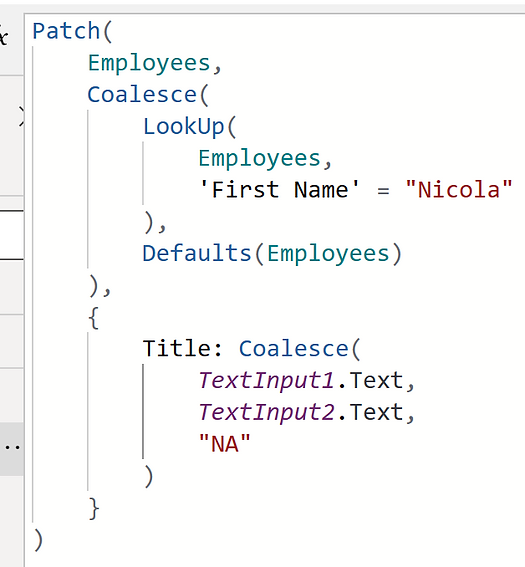
Patch(Table, [Record], {Field1: Value, Field2: Value...})It’s common to see the second part of the formula – [Record] – change depending on whether you want to create or edit an item. For creating a new item, it’s likely to look like:
Patch(Table, Defaults(Table), {Field1: Value, Field2: Value...})For editing an item, perhaps something like this that will target a specific row with a unique identifier:
Patch(Table, {ID:ID}, {Field1: Value, Field2: Value...})
Nice and easy for single records, but what about multiple? Patch will be our go-to for that too, but the how will have to change if we want it to perform well.
Scenario
In my scenario, I have a static set of questions stored in a table that several employees will need to answer. The questions are visible to users in a collection, via a gallery. User responses are also captured in the same collection. The Power Apps patch function is used for the data transactions back to our data source.
This is the concept of ‘dynamic forms’ in Power Apps, it’s a very powerful and flexible data collection technique. I plan to cover dynamic forms in an article and app example soon, but I had to cover data saving methods first. It would be a mammoth article to cover both topics in one!
In my sample app, the OnStart property builds the question data using the following Power Fx:
Collect(
colQuestions,
ForAll(
Sequence(100),
{
myQuestionID: Value,
myQuestion: $"Question {Value}",
myResponse: $"Response {Value}"
}
)
);If you’ve followed my blog for a while, you’ll already know I’m a fan of the sequence function. Generating random data is another great use for it. You can even add in a cheeky rand or randbetween if you’re feeling extra saucy.
In reality this kind of static data may reside in a Dataverse table or SharePoint list. Either way, with our 100 rows of sample data, let’s build out and test a few ways to create and edit the multiple rows. For that, we need some tables.
Structure
I have three Dataverse tables in my solution, each supporting a single method.
Both the ForAll example and Schema Match example tables have the following structure:
| Field Name | Field Type |
|---|---|
| Response ID | Single Line of Text |
| QuestionID | Number |
| Question | Single Line of Text |
| Response | Single Line of Text |
The JSON example table has the following structure:
| Field Name | Field Type |
|---|---|
| Response ID | Single Line of Text |
| Response | Multiple Lines of Text |
ForAll(Patch)
This method adds or edits rows in your data source, one at a time. The ForAll function evaluates each row, then carries out the required actions. This method is commonly used in Power Apps to create or edit multiple rows.
In my experience, it’s also the slowest. The more rows you try to process, the slower it gets. Patch is an expensive operation, so to call it many times within a loop is bound to have a performance impact. Let’s test this out by processing the 100 rows in my colQuestions collection.
This is the Power Fx for the ForAll(Patch) approach that will create 100 rows in the ForAll example table:
// Patch all rows from sample data to Dataverse, using ForAll(Patch) approach
ForAll(
colQuestions,
Patch(
'ForAll examples',
Defaults('ForAll examples'),
{
ResponseID: "ABC123",
QuestionID: myQuestionID,
Question: myQuestion,
Response: myResponse
}
)
);In my testing, processing the 100 records would take anywhere from 12-28 seconds. Would that be a great experience for users? Probably not.
Patch(ForAll)
Swapping the Patch and ForAll around will yield a far better experience. The ForAll provides the data structure for processing that sits within a single Patch statement. As the Patch is doing the work, it’s a far cheaper transaction and therefore much quicker when it’s only run once.
Here’s the Power Fx for this method:
// Patch all rows from sample data to Dataverse, using Patch(ForAll) approach
Patch('ForAll examples',
ForAll(colQuestions,
{
ResponseID: "ABC123",
QuestionID: myQuestionID,
Question: myQuestion,
Response: myResponse
}
)
);This creates the rows in the ForAll example table in rapid time. During my testing of processing the 100 records of colQuestions, this approach would typically take 1-2 seconds.
A huge thanks to fellow Power Apps Forum Super User, Randy Hayes, for reaching out and sharing this technique with me. He mentioned to me to how widely assumed it is that ForAll(Patch) is the go-to method, and how it gives the ForAll function a bad name. We see the ForAll(Patch) approach a lot in questions on the forums.
When ForAll and Patch are together correctly, they’re very powerful – as the Patch(ForAll) approach testifies.
Schema Match
Schema matching, or ‘upsert’ is a very popular technique for patching multiple rows. It was a widely exposed technique since the excellent Matthew Devaney posted his ‘Patch 10x Faster‘ article back in 2020. It’s also documented in this Microsoft article but not sure how well known that is. Microsoft’s articles don’t have pictures of cats, so that might be why.
The idea of this technique is to replicate the structure of the data source you want to send data to. We can then write a patch statement in a slightly different way that will perform all creations and updates at once.
We’ll use colQuestions to create records in the Schema Match example table.
Config
1- Create a collection that mimics the schema of the data source we’ll be updating. We’ll be creating new records, so the collection shouldn’t have any rows.
There’s a couple of ways you can do this; one is to use FirstN:
//Create empty collection to match schema of destination tbl using FirstN/0 method
ClearCollect(
colSchemaMatchResponse,
FirstN('Schema Match examples', 0));Another is to filter for a condition that will never return any rows of data:
/*
Create empty collection to match schema of destination tbl.
Filter criteria should never yield a result, we need a blank collection
*/
ClearCollect(
colSchemaMatchResponse,
Filter(
'Schema Match examples',
ResponseID = "XXXX XXXX"
)
);Either way is good. Again, the object is to create a blank collection that matches the schema of the table we’ll be saving records to.
2- For our scenario, users have input their responses into the colQuestions collection. We need to copy the data over to the created colSchemaMatchResponse collection. This will set up the patch to be super efficient.

/*
Patch all rows to the created collection
ForAll is ok here as it's just pushing rows from one collection to another.
*/
Collect(
colSchemaMatchResponse,
ForAll(
colQuestions,
{
ResponseID: "ABC123",
QuestionID: myQuestionID,
Question: myQuestion,
Response: myResponse
}
)
);3- Use the Power Apps patch function to patch the collection back to the data source:
// Patch collection back to data source
Patch(
'Schema Match examples',
colSchemaMatchResponse
);Another lightening fast technique, averaging around 1-2 seconds to process 100 records in my testing.
A real advantage of this technique is that the patch statement here will handle creating and editing items. If we wanted to edit the items submitted, we’d simply rebuild colSchemaMatchResponse using a filter that will return data:
/*
Create collection to match schema of destination tbl.
Filter criteria based on a specified set of responses with the samme ResponseID of ABC123
*/
ClearCollect(
colSchemaMatchResponse,
Filter(
'Schema Match examples',
ResponseID = "ABC123"
)
);Any changes made by a user can be configured to update the collection directly. When done, the same Power Apps patch syntax can be used:
// Patch collection back to data source
Patch(
'Schema Match examples',
colSchemaMatchResponse
);It will seamlessly update any row in the data source table, where a change has occurred in the collection. It will leave all other rows, keeping the Modified date and time in tact for unedited rows.
This has been my favourite method for some time, especially when it comes to designing dynamic forms (a reminder that I’ll be writing about this in more detail very soon). However, there’s a new option that I’m becoming a fan of more and more!
JSON / Parse JSON
I’ll get to the method shortly, but first I’d like to explain the why. I was lucky enough to attend the European SharePoint Conference (ESPC) in Denmark in 2018. I remember I followed Fabian Williams on Twitter shortly before the conference and saw that he had this session, which I attended. At the time, the majority of the session went waaaaaaaaay over my head, but a concept that stuck out to me was storing data in JSON document databases.
Microsoft host such services, such as Azure Cosmos DB. In this service, data is stored as documents, but not the traditional documents you might find in a SharePoint library. In Azure Cosmos DB and other NoSQL services, a document is a unit of data typically stored in JSON format. There are no tables, structure or relationships but can still use many languages to query data. Storing data this way is fast and can adapt easily to schema changes. This is a good summary of JSON document databases if you’d like to read further.
I’ve wanted to be able to save data in similar ways with Power Apps developments. We’ve had the JSON function for ages so that can convert data easily enough. But how to get the data back into our apps? That’s been a challenge right up until October 2023, when the ParseJSON function for Power Apps went GA.
Concept
For our colQuestions scenario, the concept is:
1- Convert the whole colQuestions collection (100 rows of data) into a JSON object.
2- Patch the JSON example table to create one new row. The JSON object (storing 100 rows of data) will be saved in a Multiple Line of Text field in the created row.
3- When the data needs to be viewed & edited in the Power App, use the ParseJSON function to rebuild the colQuestions collection.
Saving data
I’ll also use the schema matching method here, again it avoids needing any Defaults or specifying ID’s in a Power Apps patch function.
1- Create the empty collection:
// Create empty collection to match schema of destination tbl using FirstN method
ClearCollect(
colJSONResponse,
FirstN('JSON examples', 0));2- Collect our single row of data into the created collection. For our response field, we are using the JSON function to convert colQuestions into our JSON document.
TIP: When using the JSON function in Power Apps, if you want the output to be easier on the eye, make sure you add ‘JSONFormat.IndentFour’ to the format property of the function.
/*
Patch single row (with JSON object) to the created collection.
colQuestions is converted to JSON as part of the Collect.
*/
Collect(
colJSONResponse,
{
ResponseID: "ABC123",
Response: JSON(
colQuestions,
JSONFormat.IndentFour
)
}
);In my testing, it takes on average 0-1 second to create our single row of data, with all 100 rows from colQuestions nested within the Response column:
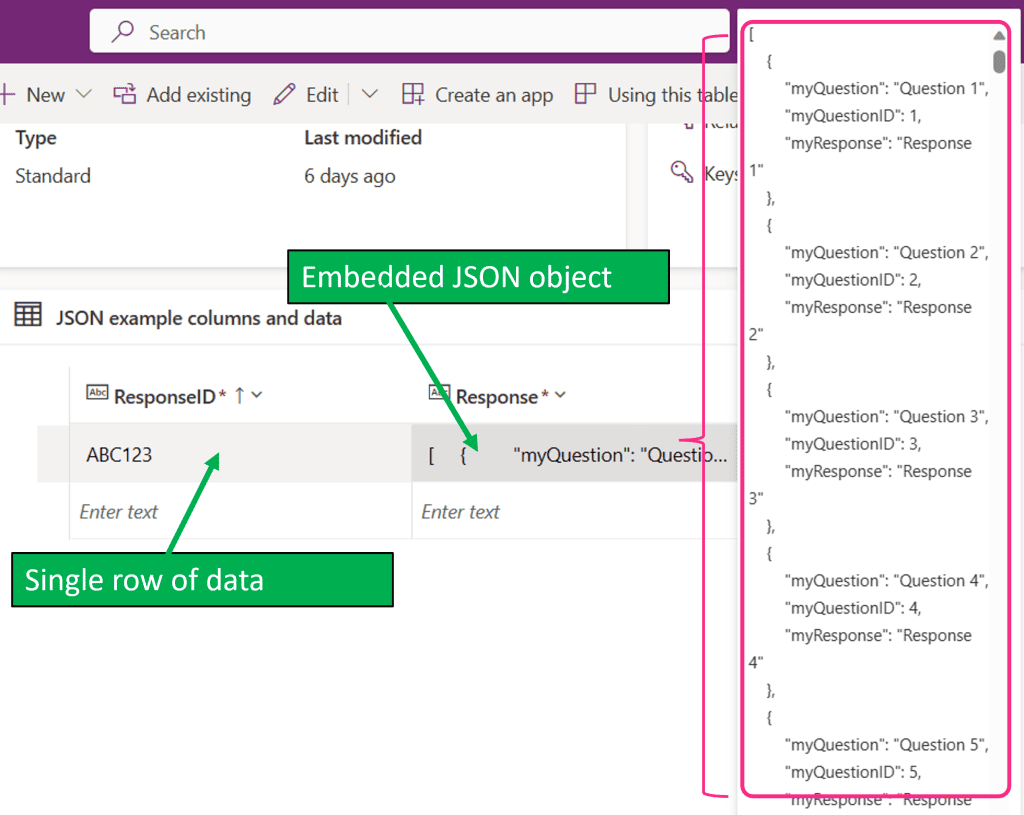
Returning data
Chances are, data being saved by a Power App also needs to be viewed, maybe even edited. Up steps the ParseJSON function.
I have a gallery in my app which shows the x1 row of data created above. I’ve added a button to the gallery that will convert the JSON back to our colQuestions collection:

The button has the following Power Fx in the OnSelect property:
// Create collection with saved JSON string
ClearCollect(
colQuestions,
ForAll(
ParseJSON(ThisItem.Response),
{
myQuestionID: Value(ThisRecord.myQuestionID),
myQuestion: Text(ThisRecord.myQuestion),
myResponse: Text(ThisRecord.myResponse)
}
)
)Sorted, colQuestions rebuilt. The user can now make edits against the collection, then update the single row in the table with an updated JSON conversion of the collection.
Returning the data also took 0-1 second over many tests. So the overall process with the JSON / ParseJSON method to patch multiple rows is insanely fast.
Speed Test
I thought I’d test all three methods with increasing number of rows, as I wanted to see how each one scaled with more data to save. I calculated average time based on over 20 runs of each method. The graph below shows the outcome:
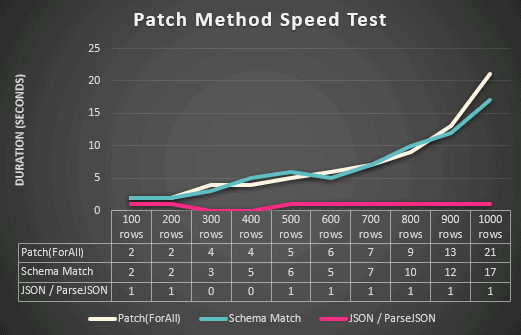
There’s unlikely to be a real-world business scenario of needing to simultaneously patch 1,000 rows back to a data source. Mind you, I’ve seen and heard all sorts of requirements in consultancy! Jokes aside, I thought it was an interesting test. I expected the duration of Patch(ForAll) and Schema Match to increase with the number of rows to process. It makes total sense, because both methods are physically creating rows of data. More rows = longer to run.
I thought there might be some fluctuation in the JSON method though; maybe the size of the collection to convert to JSON would take longer, so creating the row would take longer too. But then, it’s just creating a single row – every time. The size of the JSON object being stored doesn’t appear to have an impact when saving, or indeed when using ParseJSON to reload the data. So regardless of number of columns or rows, the JSON / ParseJSON is incredibly fast and consistent.
Best method to use
Choosing between storing data as JSON versus a traditional table structure depends on the specific need and characteristics of your application. It’s likely to come down to factors such as reporting, scalability, development speed, types of queries you’ll need to perform and the nature of the data. There are positives; reducing number of tables, simplified structure, less storage & flexible schemas. But with that might come lack of joins (relationships) to other data, integration with other systems or ability to query information in the JSON objects.
A good example of this for canvas apps is the age-old SharePoint or Dataverse debate. If you wanted to search or find text in a JSON object saved in a SharePoint list, good luck. Delegation will not be your friend. Dataverse however will allow those functions to be performed.
Most of us in the Power Platform space I’m sure are at one with tables, relationships, itemised rows and so on. So the JSON approach is likely to be completely left field, but one that deserves as much attention & usage as ever-popular schema match approach.
To support the logic in this article, I created a solution containing x3 Dataverse tables and a canvas app. If you want to test out the methods for yourselves, you can download the solution from here FOR FREE. The solution is unmanaged so you can see the underlying code.
Thanks for reading! If you liked this article and want to receive more helpful tips about Power Platform every week, don’t forget to subscribe 😊
About the author
I’m Craig! I live in the UK and I’ve used a variety of Microsoft technologies for over 20 years, including Visual Basics, SQL, SSRS, SharePoint (on-premise and Online), InfoPath, SharePoint Designer and most of the wider Microsoft 365 services. Since 2016, I’ve been heavily absorbed in the Power Platform stack; back then it was Power BI, PowerApps (without the space!) and Flow. It’s changed and grown a bit since. I currently work for a large Microsoft Gold Partner in the UK, as a Power Platform / Low Code Ecosystem Architect.
References
White, C. (2023). Patch Multiple Rows In Power Apps Like A Jedi!, Available at: https://platformsofpower.net/patch-multiple-rows-in-power-apps-like-a-jedi/ [Accessed: 25th March 2024].